- Published on
Four Node Raspberry Pi 4 Cluster - Python on All Cores
- Authors

- Name
- Joshua Jerred

With the current Raspberry Pi shortage this doesn't seem very relevant, but I purchased my four Pi 4s in 2020 when they were much easier to find. This is a small extension of the work done by Michael Klements from the-diy-life.com as he created the original multi-node benchmark. The primary thing that was missing from his project was the use of all cores on the Pi.
Python is very powerful, but single-threaded, like many other languages, unless you use external libraries. Another thing to think about is that with my cluster of four nodes, if we were to split single threaded work between them we would only be working on four cores out of the sixteen that are available. Each Pi has has a Quad core Cortex-A72, so we're throwing away 12 cores. My four node cluster would be almost equivalent to a single multi-threaded Pi.
Check for Primes - Even Job Splitting
Definitions: Node - A single Raspberry Pi within the cluster. Core - A single logical CPU, of which each node in the cluster has 4.
In this example, we are counting the occurrences of prime numbers within a range of 1 up to N numbers. There are faster ways to calculate prime numbers, but we are looking to simulate computational work. This calculating primes work can easily be split between multiple nodes, but it must be done in a fair manner. I've found that balancing work between nodes when working on any task can be a challenge at times. You can simply just split a list of numbers between 1 and N into even quarters, but this would result in some nodes being assigned more work than others. This is because the amount of time that it takes determine if a number is prime or not increases with it's value. The complexity increases at O(n*sqrt(n)). The final test in this example is N = 10,000,000. The last number alone would take up to 3163 iterations to find out if it was prime, while the first only takes one.
I will be using the following algorithm which I have left in it's python form as I think it's easiest to understand that way. Each node is aware of the total number of nodes and it's own node number, which starts at 1.
start = (node_number * 2) + 1
end = N
skip_value = number_of_nodes * 2
range(start, end, skip)
Or even more helpful, here is an example in visual form.

Now we just need a way to communicate this with all of the nodes.
Thankfully we have 'Message Passing Interface' or MPI to help us communicate with the nodes. Inside of Python we have mpi4py which helps us connect to MPI. After setting up a quick SSH configuration file, mirroring it to the head node, and transferring SSH keys to all of the nodes, we can get started!I will not be outlining those steps here as Michael did a great job doing that, you can find his article here.
Now that all of the nodes can communicate with each other we can use mpi4py. With mpi4py in our Python script we can communicate what work needs to be done and collect the data from each node as they finish. The head node can then deliver the results. A similar splitting algorithm often times needs to be implemented, but I will be using the map.pool() function from the Python multiprocessing library.
Using a pool allows us to have a common list of tasks that the workers/threads can grab from. Although this may not be the fastest way, the data shows that it does work. All of this can be seen in the documented code here. The comments in those files can help you to understand what exactly is happening.
That's really all it takes to get parallelizing with Python. Let's give it a try.
Tests
Hardware
The hardware for my cluster includes 4x Raspberry Pi 4s, 2gb, base clock speed. Instead of finding a place to plug four wall outlets in, they all have Pi POE+ hats. For power delivery I'm using a Netgear G530SP which is a super cheap five port, 1 Gbps, 63W, unmanaged switch.
Software
The repo includes two Python files and a Makefile. One Python file includes mpi4pi for working with the cluster, the other does not include it for local, single node testing. Each script can be executed in the following way:
python3 [filename].py [number to test up to] [-s for simple output] [threads per node]
But we need to execute the Python file with mpiexe for the crucial MPI network communication. This also must be done on the head node. My command looked a little something like this:
mpiexec -n 4 --host node-1,node-2,node-3,node-4 python3 ~/mpiTests/primeMP.py 100 -s 4
To automate this testing I went with what I considered to be the easiest method, a Makefile. This could be done in a thousand better ways, but I love the simplicity of calling make from the command line. I also created an action for transferring the files from my workstation to all four nodes via rsync.
There are a few basic actions:
make sync - rsync current directory between host and all nodes
make check-cluster - run on head node to verify connection
make test - run all tests
The tests can be run individually with make and one of the following: fournode-fourcore fournode-onecore local-fourcore local-onecore
Each test iterates over the values of the variable testVal which is currently set to 100 1000 10000 100000 1000000 10000000.
Upon running make test you'll see an output similar to this:
Four Nodes, 16 Threads
Primes in: 100 Found: 25 Seconds: 0.14 Nodes: 4 Threads Per Node: 4
.
.
.
Results
Pi Cluster
Four Nodes, 16 Threads
fournode-fourcore
Primes in: 100 Found: 25 Seconds: 0.14 Nodes: 4 Threads Per Node: 4
Primes in: 1000 Found: 168 Seconds: 0.11 Nodes: 4 Threads Per Node: 4
Primes in: 10000 Found: 1229 Seconds: 0.09 Nodes: 4 Threads Per Node: 4
Primes in: 100000 Found: 9592 Seconds: 0.13 Nodes: 4 Threads Per Node: 4
Primes in: 1000000 Found: 78498 Seconds: 0.8 Nodes: 4 Threads Per Node: 4
Primes in: 10000000 Found: 664579 Seconds: 18.2 Nodes: 4 Threads Per Node: 4
Four Nodes, 4 Threads
fournode-onecore
Primes in: 100 Found: 25 Seconds: 0.09 Nodes: 4 Threads Per Node: 1
Primes in: 1000 Found: 168 Seconds: 0.11 Nodes: 4 Threads Per Node: 1
Primes in: 10000 Found: 1229 Seconds: 0.22 Nodes: 4 Threads Per Node: 1
Primes in: 100000 Found: 9592 Seconds: 0.18 Nodes: 4 Threads Per Node: 1
Primes in: 1000000 Found: 78498 Seconds: 2.5 Nodes: 4 Threads Per Node: 1
Primes in: 10000000 Found: 664579 Seconds: 63.88 Nodes: 4 Threads Per Node: 1
Single Node, 4 Threads (Local, no MPI)
local-multicore
Primes in: 100 Found: 25 Seconds: 0.06 Nodes: 1 Threads Per Node: 4
Primes in: 1000 Found: 168 Seconds: 0.06 Nodes: 1 Threads Per Node: 4
Primes in: 10000 Found: 1229 Seconds: 0.07 Nodes: 1 Threads Per Node: 4
Primes in: 100000 Found: 9592 Seconds: 0.19 Nodes: 1 Threads Per Node: 4
Primes in: 1000000 Found: 78498 Seconds: 2.77 Nodes: 1 Threads Per Node: 4
Primes in: 10000000 Found: 664579 Seconds: 70.04 Nodes: 1 Threads Per Node: 4
Single Node, 1 Thread (Local, no MPI)
local-onecore
Primes in: 100 Found: 25 Seconds: 0.0 Nodes: local Threads Per Node: 1
Primes in: 1000 Found: 168 Seconds: 0.0 Nodes: local Threads Per Node: 1
Primes in: 10000 Found: 1229 Seconds: 0.02 Nodes: local Threads Per Node: 1
Primes in: 100000 Found: 9592 Seconds: 0.38 Nodes: local Threads Per Node: 1
Primes in: 1000000 Found: 78498 Seconds: 9.66 Nodes: local Threads Per Node: 1
Primes in: 10000000 Found: 664579 Seconds: 259.0 Nodes: local Threads Per Node: 1
Ryzen 7 5800X
Just for a point of comparison, I ran the same tests on a Ryzen 7 5800X with the addition of an 8 thread test.
Ryzen 7 5800X, 8 Threads
local-eightcore
Primes in: 100 Found: 25 Seconds: 0.01 Nodes: 1 Threads Per Node: 8
Primes in: 1000 Found: 168 Seconds: 0.01 Nodes: 1 Threads Per Node: 8
Primes in: 10000 Found: 1229 Seconds: 0.01 Nodes: 1 Threads Per Node: 8
Primes in: 100000 Found: 9592 Seconds: 0.02 Nodes: 1 Threads Per Node: 8
Primes in: 1000000 Found: 78498 Seconds: 0.31 Nodes: 1 Threads Per Node: 8
Primes in: 10000000 Found: 664579 Seconds: 7.73 Nodes: 1 Threads Per Node: 8
Ryzen 7 5800X, 4 Threads
local-fourcore
Primes in: 100 Found: 25 Seconds: 0.01 Nodes: 1 Threads Per Node: 4
Primes in: 1000 Found: 168 Seconds: 0.01 Nodes: 1 Threads Per Node: 4
Primes in: 10000 Found: 1229 Seconds: 0.01 Nodes: 1 Threads Per Node: 4
Primes in: 100000 Found: 9592 Seconds: 0.03 Nodes: 1 Threads Per Node: 4
Primes in: 1000000 Found: 78498 Seconds: 0.57 Nodes: 1 Threads Per Node: 4
Primes in: 10000000 Found: 664579 Seconds: 14.51 Nodes: 1 Threads Per Node: 4
Ryzen 7 5800X, 1 Thread
local-onecore
Primes in: 100 Found: 25 Seconds: 0.01 Nodes: 1 Threads Per Node: 1
Primes in: 1000 Found: 168 Seconds: 0.01 Nodes: 1 Threads Per Node: 1
Primes in: 10000 Found: 1229 Seconds: 0.01 Nodes: 1 Threads Per Node: 1
Primes in: 100000 Found: 9592 Seconds: 0.08 Nodes: 1 Threads Per Node: 1
Primes in: 1000000 Found: 78498 Seconds: 1.92 Nodes: 1 Threads Per Node: 1
Primes in: 10000000 Found: 664579 Seconds: 51.47 Nodes: 1 Threads Per Node: 1
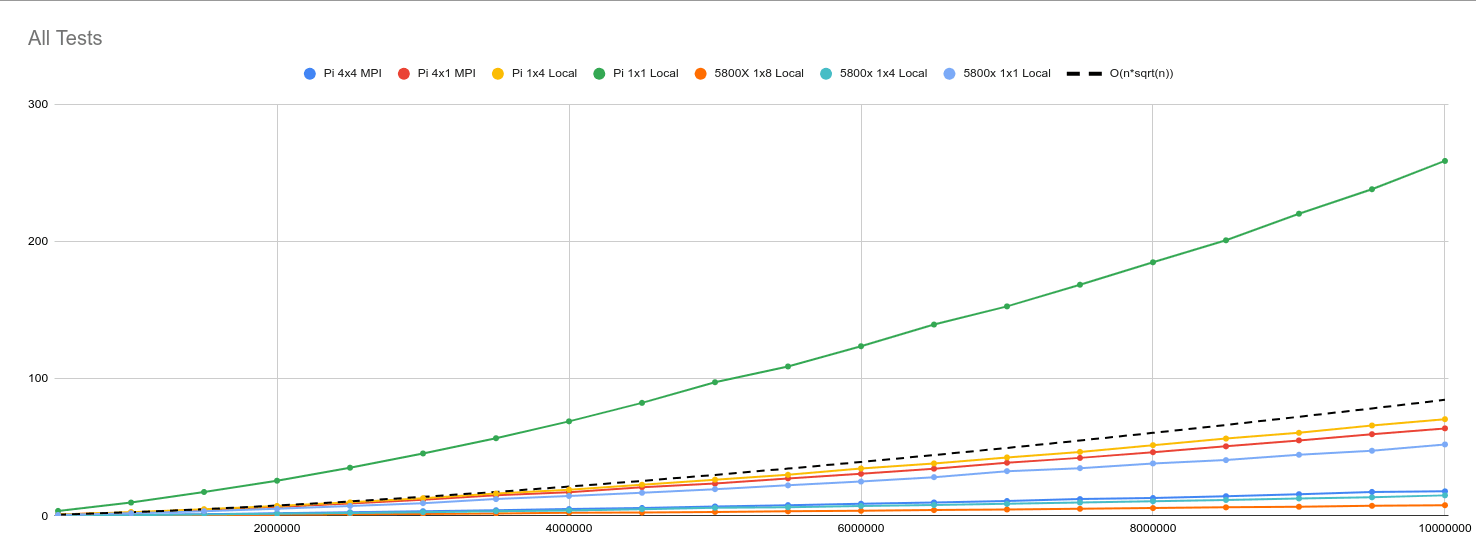
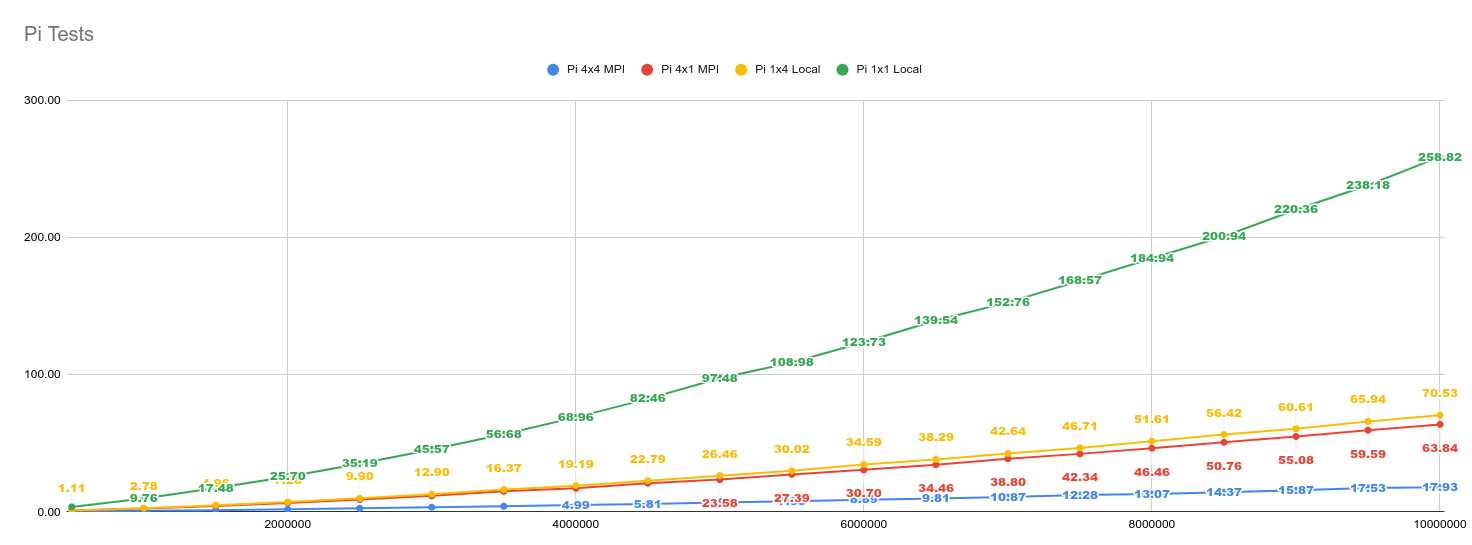
Graphical Data
In these graphs, the x-axis shows the number of number to check for primality. The y-axis shows the time it took to find all the primes in that range. Each line represents a different configuration labeled as nodesXthreads.
Three iterations of each test were run and the average time is used. Tests were run with values from 500,000 up to 10,000,000 in increments of 500,000.
There was a small anomaly in the first test of three within the 4 node, 1 thread tests. The time was about 20 seconds slower than the other two tests. It is still included in the graph.
One interesting observation is that the 4 node, 1 thread test is faster than the 1 node, 4 thread test. My assumption here is that it's a result of using the Python thread pool on the local tests. With Python, the Global Interpreter Lock (GIL) (prevents multiple threads from executing Python bytecodes at once.)[https://wiki.python.org/moin/GlobalInterpreterLock]
Conclusion
This is mostly just a representation of what you can do with MPI within Python. There are many applications and this should be enough to get started on useful projects.